Welcome to sukbear's Blog!
Talk is cheap, Show me the code-
salt加密
salt
1.用户注册时,在密码上撒一些盐。生成一种味道,记住味道。 2.用户再次登陆时,在输入的密码上撒盐,闻一闻,判断是否和原来的味道相同,相同就让你吃饭。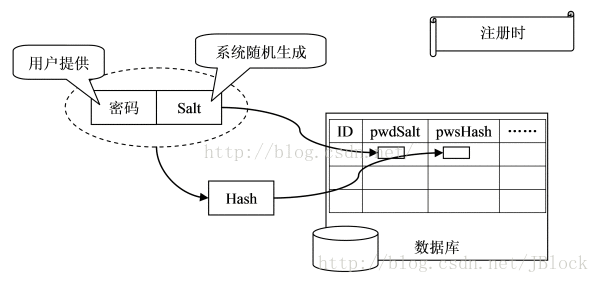
注册
1.用户注册,系统随机产生salt值。 2.将salt值和密码连接起来,生产Hash值。 3.将Hash值和salt值分别存储在数据库中。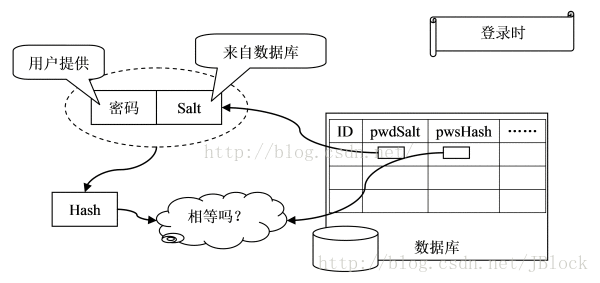
登陆时
1.系统根据用户名找到与之对应的密码Hash。 2.将用户输入密码和salt值进行散列。 3.判断生成的Hash值是否和数据库中Hash相同。
-
低版本IE中点击空block元素的问题
-
使用 JavaScript 创建并下载文件
本文将介绍如何使用 JavaScript 创建文件,并自动/手动将文件下载。这在导出原始数据时会比较方便。
先上代码
/** * 创建并下载文件 * @param {String} fileName 文件名 * @param {String} content 文件内容 */ function createAndDownloadFile(fileName, content) { var aTag = document.createElement('a'); var blob = new Blob([content]); aTag.download = fileName; aTag.href = URL.createObjectURL(blob); aTag.click(); URL.revokeObjectURL(blob); }很简单对吧,直接调用这个方法,传入文件名和文件内容,程序新建 a 标签,新建 Blob 对象,将文件名赋给 a 标签,同时将 Blob 对象作为 Url 也赋给 a 标签,模拟点击事件,自动下载成功,最后再回收内存。下面我们来看看具体是怎么操作的。
-
Java8尝鲜
Java8 Tutorial
接口默认方法
interface fun{ double calculate(int a); default double method(int a) { return a++; } }接口
fun中除了抽象方法计算接口公式还定义了默认方法methodLambda表达式(Lambda expressions)
beforeList<String> names = Arrays.asList("peter", "anna", "mike", "xenia"); Collections.sort(names, new Comparator<String>() { @Override public int compare(String a, String b) { return b.compareTo(a); } });nowCollections.sort(names, (String a, String b) -> { return b.compareTo(a); });函数式接口(Functional Interfaces)
“函数式接口”是指仅仅只包含一个抽象方法,但是可以有多个非抽象方法(也就是上面提到的默认方法)的接口。
注解
@FunctionalInterface@FunctionalInterface public interface fun<F, T> { T convert(F from); // default method default double method(int a) { return a++; } }Lambda表达式(Lambda expressions) 使用的前提就是要是函数式接口。Functions
Suppliers
Supplier 接口产生给定泛型类型的结果。 与 Function 接口不同,Supplier 接口不接受参数。
Supplier<Person> personSupplier = Person::new; personSupplier.get(); // new PersonConsumers
Consumer 接口表示要对单个输入参数执行的操作(void 方法)。
System.out::println;Consumer<Person> greeter = (p) -> System.out.println("Hello, " + p.firstName); greeter.accept(new Person("Luke", "Skywalker"));Optionals
Optionals不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optionals的工作原理。
Optional 是一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是有时却什么也没有返回,而在Java 8中,你应该返回 Optional 而不是 null。
Streams(流)
java.util.Stream表示能应用在一组元素上一次执行的操作序列。Stream 操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如java.util.Collection的子类,List 或者 Set, Map 不支持。Stream 的操作可以串行执行或者并行执行。Filter(过滤)
过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于中间操作,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
stringList .stream() .filter((s) -> s.startsWith("a")) .forEach(System.out::println);forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda 表达式本身是可以重用的,非常方便。
Sorted(排序)
排序是一个 中间操作,返回的是排序好后的 Stream。如果你不指定一个自定义的 Comparator 则会使用默认排序。
// 测试 Sort (排序) stringList .stream() .sorted() .filter((s) -> s.startsWith("a")) .forEach(System.out::println);Map(映射)
中间操作 map 会将元素根据指定的 Function 接口来依次将元素转成另外的对象。
下面的示例展示了将字符串转换为大写字符串。你也可以通过map来讲对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
// 测试 Map 操作 stringList .stream() .map(String::toUpperCase) .sorted((a, b) -> b.compareTo(a)) .forEach(System.out::println);并行流
并行Stream是在多个线程上同时执行。下面的例子展示了是如何通过并行Stream来提升性能: 首先我们创建一个没有重复元素的大表:
int max = 1000000; List<String> values = new ArrayList<>(max); for (int i = 0; i < max; i++) { UUID uuid = UUID.randomUUID(); values.add(uuid.toString()); }Sequential Sort(串行排序)
//串行排序 long t0 = System.nanoTime(); long count = values.stream().sorted().count(); System.out.println(count); long t1 = System.nanoTime(); long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0); System.out.println(String.format("sequential sort took: %d ms", millis));1000000 sequential sort took: 709 ms//串行排序所用的时间Parallel Sort(并行排序)
//并行排序 long t0 = System.nanoTime(); long count = values.parallelStream().sorted().count(); System.out.println(count); long t1 = System.nanoTime(); long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0); System.out.println(String.format("parallel sort took: %d ms", millis));1000000 parallel sort took: 475 ms//串行排序所用的时间多重注解
-
hello jekyll!
You’ll find this post in your
_postsdirectory. Go ahead and edit it and re-build the site to see your changes. You can rebuild the site in many different ways, but the most common way is to runjekyll serve, which launches a web server and auto-regenerates your site when a file is updated.To add new posts, simply add a file in the
_postsdirectory that follows the conventionYYYY-MM-DD-name-of-post.extand includes the necessary front matter. Take a look at the source for this post to get an idea about how it works.Jekyll also offers powerful support for code snippets:
def print_hi(name) puts "Hi, #{name}" end print_hi('Tom') #=> prints 'Hi, Tom' to STDOUT.Check out the Jekyll docs for more info on how to get the most out of Jekyll. File all bugs/feature requests at Jekyll’s GitHub repo. If you have questions, you can ask them on Jekyll’s dedicated Help repository.
Block Mathjax
Inline Mathjax $a \neq b$
-
Tomcat结构、处理请求过程
Tomcat是一个基于组件形式的的Web容器,由Server(服务器)、Service(服务)、Connector(连接器)、Engine(引擎)、Host(主机)、Context(应用服务)组。
它们在server.xml里配置:
<?xml version="1.0" encoding="UTF-8"?> <Server port="8005" shutdown="SHUTDOWN"> <Service name="Catalina"> <Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443" URIEncoding="UTF-8"/> <Connector port="8009" protocol="AJP/1.3" redirectPort="8443"/> <Engine defaultHost="localhost" name="Catalina"> <Host appBase="webapps" autoDeploy="true" name="localhost" unpackWARs="true"> <Context docBase="src-ConsumptionAnalysisSystem" path="/ConsumptionAnalysisSystem" reloadable="true" source="org.eclipse.jst.jee.server:src-ConsumptionAnalysisSystem"/> </Host> </Engine> </Service> </Server>Tomcat组件

Server:代表整个Tomcat,它包含所有的容器;
Service:相当于一个集合,包含多个Connector(连接)、一个Engine(引擎),它还负责处理所有Connector(连接)获取的客户请求;
Connector:一个Connector(连接)在指定的接口上侦听客户的请求,并将客户的请求交给Engine(引擎)来进行处理并获得回应返回给客户请求;
Engine:一个Engine(引擎)下可以配置多个虚拟主机Host,每个主机都有一个域名,当Engine获得一个请求时,会把这个请求发送的相应的Host上,Engine有一个默认的虚拟主机,如果没有虚拟主机能够匹配这个请求,那就由这个默认的虚拟主机来进行处理请求;
Host:代表一个Virtual host,每个虚拟主机都和某个网络域名想匹配,每个虚拟主机下面可以部署一个或者多个web app,每个web对应一个context,有一个context path,当一个host获取请求时,就把该请求匹配到某个context上;
Context:一个context对应一个web aplication,一个web由一个或多个servlet组成,Context在创建的时候将根据配置文件CATALINA_HOME/conf/web.xml和WEBAPP_HOME/WEB-INF/web.xml载入servlet类,当context获取请求时,讲在自己的映射表中需找相匹配的servlet类,如果找到,则执行该类,获得请求的回应,并返回。